We propose Mesh4D, a feed-forward model for monocular 4D mesh reconstruction. Given a monocular video of a dynamic object, our model reconstructs the object’s complete 3D shape and motion, represented as a deformation field. Our key contribution is a compact latent space that encodes the entire animation sequence in a single pass. This latent space is learned by an autoencoder that, during training, is guided by the skeletal structure of the training objects, providing strong priors on plausible deformations. Crucially, skeletal information is not required at inference time. The encoder employs spatio-temporal attention, yielding a more stable representation of the object’s overall deformation. Building on this representation, we train a latent diffusion model that, conditioned on the input video and the mesh reconstructed from the first frame, predicts the full animation in one shot. We evaluate Mesh4D on reconstruction and novel view synthesis benchmarks, outperforming prior methods in recovering accurate 3D shape and deformation.
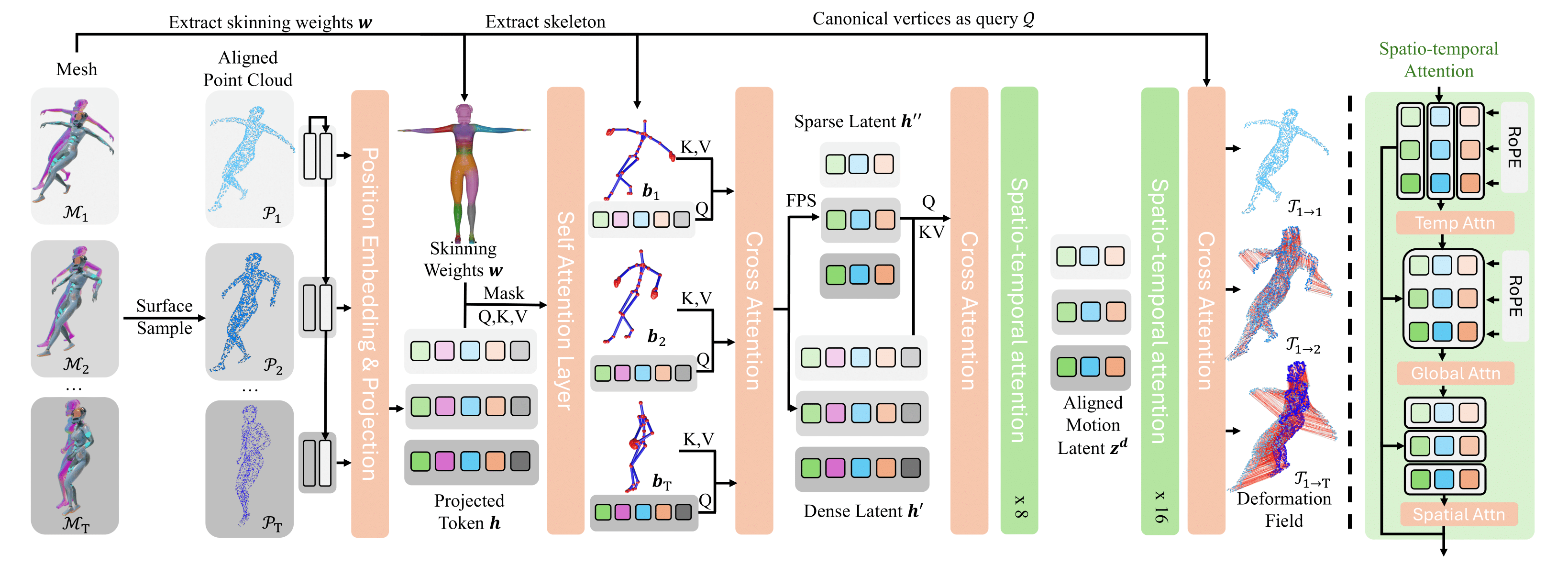
Overall Deformation VAE pipeline. (Left) Given a sequence of 3D meshes as input, we first uniformly sample a sequence of corresponding points. We inject the skeleton information by using masked self- and cross-attention. Then, a Farthest Point Sampling (FPS) at spatial dimension is performed to compress the latent, followed by 8 layers of spatio-temporal attention. The deformation field is decoded by layers of spatio-temporal attention, followed by a cross attention where canonical vertices serve as query points. (Right) Each of our spatio-temporal attention layers sequentially performs temporal attention, global attention, and spatial attention. For temporal and global attention, we additionally apply 1D RoPE embedding on the temporal dimension.
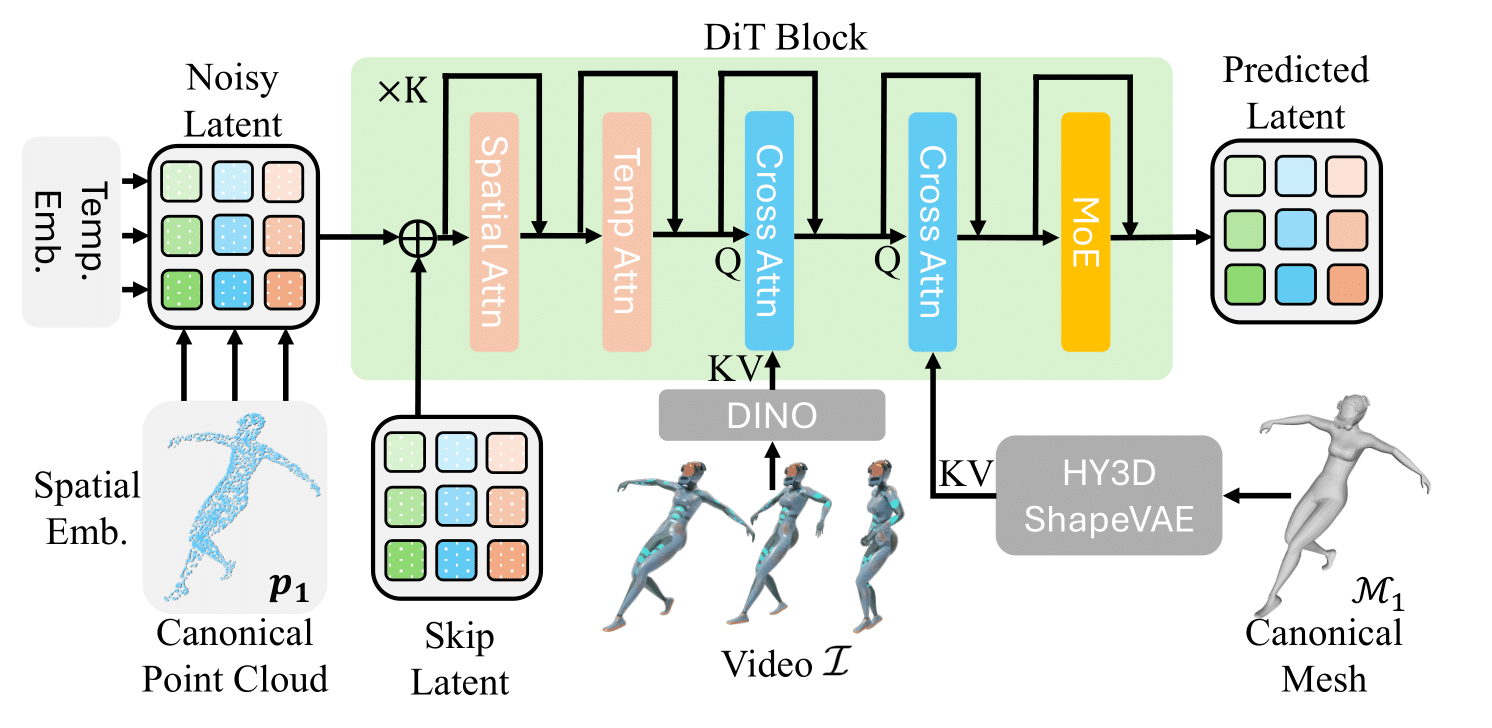
Overall deformation diffusion model pipeline. We build it based on HY3D 2.1 shape diffusion model with additional spatial and temporal embedding as well as cross attention layer to condition the deformation field generation on the canonical mesh and input video.
The authors of this work were supported by Clarendon Scholarship, NTU SUG-NAP, NRF-NRFF17-2025-0009, ERC 101001212-UNION, and EPSRC EP/Z001811/1 SYN3D.
We thank Jiraphon Yenphraphai for discussing the experiments of ShapeGen4D with us.
We thank Yushi Lan, Runjia Li, Ruining Li, Jianyuan Wang, Minghao Chen, Yufan Deng, and Gabrijel Boduljak for helpful suggestions and discussions. We also thank Angel He for proofreading.
@misc{jiang2026mesh4d,
title={Mesh4D: 4D Mesh Reconstruction and Tracking from Monocular Video},
author={Zeren Jiang and Chuanxia Zheng and Iro Laina and Diane Larlus and Andrea Vedaldi},
year={2026},
eprint={2601.05251},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2601.05251},
}